|
|
|
|
|
|
|
|
|
|
|
|
|
|
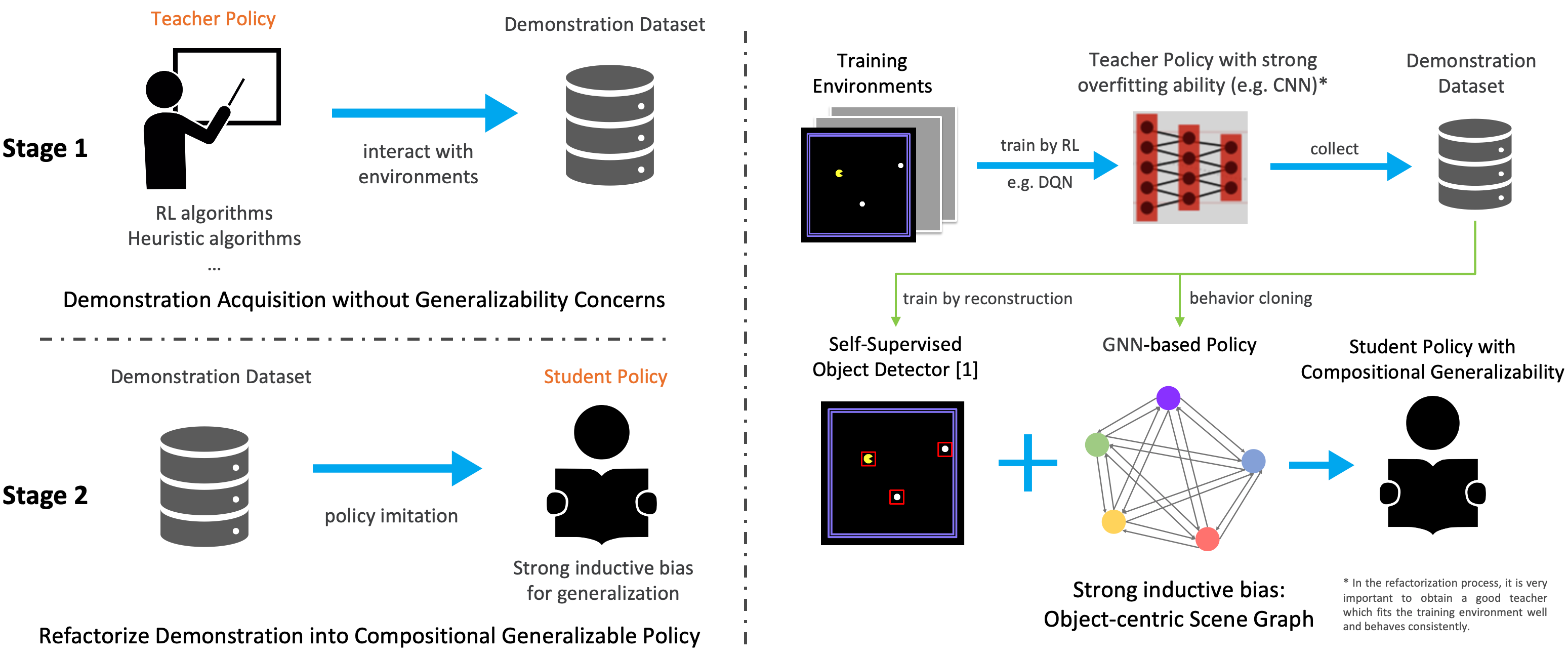
We study how to learn a policy with compositional generalizability. We propose a two-stage framework, which refactorizes a high-reward teacher policy into a generalizable student policy with strong inductive bias. Particularly, we implement an object-centric GNN-based student policy, whose input objects are learned from images through self-supervised learning. Empirically, we evaluate our approach on four difficult tasks that require compositional generalizability, and achieve superior performance compared to baselines.
 |
Tongzhou Mu*, Jiayuan Gu*, Zhiwei Jia, Hao Tang, Hao Su Refactoring Policy for Compositional Generalizability using Self-Supervised Object Proposals NeurIPS 2020 |
|
|
|
|
|
|
Multi-MNIST
|
|
Generalize to more objects
|
 |
 |
|
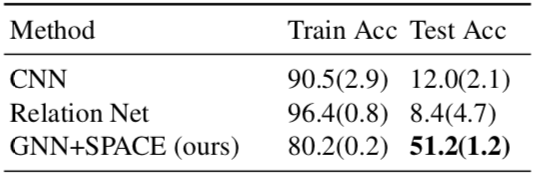
In Multi-MNIST, the task is to to calculate the summation of the digits in the image with complicated backgrounds (from CIFAR or ImageNet). Our model (GNN+SPACE) trained on images with 1 to 3 digits can generalize well to images with 4 digits. We show that object-centric graph can be a strong inductive bias for compositional generalizability. |
|
Task-relevant Knowledge Discovery
|
 |
|
Object attributes emerge when the learned object features are clustered. This figure shows the t-SNE visualization of the learned object features by the self-supervised object detector (CIFAR/ImageNet-Recon) and our policy GNN (CIFAR/ImageNet-Task). It is observed that task-driven object features are more distinguishable compared to reconstruction-driven ones. |
|
FallingDigit
|
|
Visualization of generalization
|
 |
 |
 |
|
Train on 3 digits
|
CNN-based teacher policy fails to generalize to 9 digits
|
GNN-based student policy generalizes to 9 digits
|
|
FallingDigit is a Tetris-like game. A digit is falling from the top and the player needs to control it to hit the digit with the closest value lying on the bottom. We show that the student network with object-centric graph inductive bias can refactorize the teacher policy into a compositional generalizable policy. |
|
Quantitative results of generalization
|
 |
|
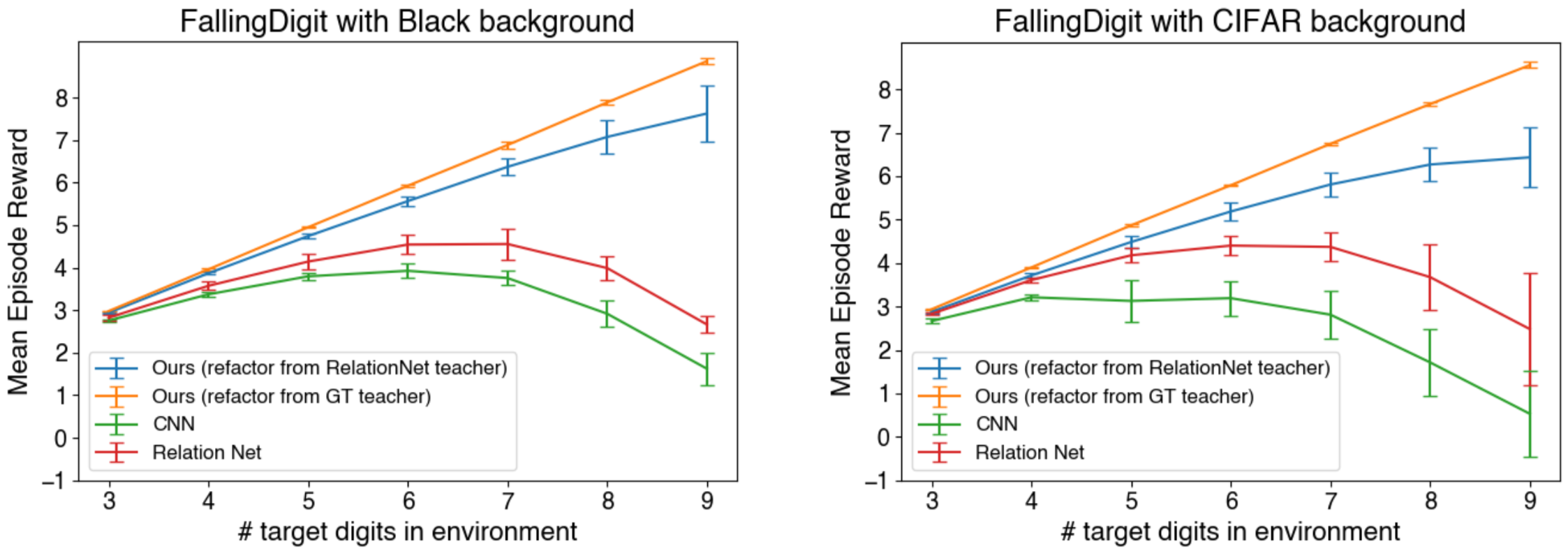
The mean rewards got by different methods in the FallingDigit environments with different target digits. Our refactorized GNN-based policy is trained on the environment with 3 target digits, and can generalize well to the environment with 9 target digits. |
|
|